
Hello Transcribe - now with Dictation
Introduction
Version 1.2.2 of “Hello Transcribe” is now on the App Store, and it has a dictation feature:
I did a lot of work in the background to understand the performance of the model and do real-time transcription, and for a long time it seemed that the TensorFlow Lite model will do the trick, but in the end I’m back with Whisper.cpp.
The important thing is I’ve laid the groundwork for supporting multi-lingual transcriptions and user-selectable accuracy/performance trade-off. More about that below.
The TensorFlow Lite detour
There is an implementation of Whisper for TensorFlow Lite, and I got it working on iOS. I wanted to compare the on-device performance of TFLite vs C++, and having more code in the Swift domain would be make things a lot simpler. Some of the things I did:
- Extracted the Mel Spectrogram step into Swift.
- Ported the token-to-word step to Swift.
- Tried to use accelerated FFT for the Mel Spectrogram step (I didn’t succeed).
- Tried CoreML acceleration but it didn’t work.
The performance of the “Tiny” model was about 100% faster in TFLite on-device, which was very promising (on my laptop TFLite is slower).
I implemented the dictation feature using the TFLite model. However, I couldn’t get the multilingual models to work. Then by a stroke of luck I discovered there’s a compilation flag for Whisper.cpp that I didn’t know about which gets performance close to TFLite — about 10% slower. But all the models work, and it’s a LOT less opaque than TFLite so I can customize it to my requirements.
Coming soon - multilingual support, user-selectable models, transcription management.
I’m confident at this point of adding better support for multi-lingual transcriptions together with a user being able to choose which Whisper model to use. The bigger models are slower and bigger, but more accurate, and have better support for languages other than English. The Tiny model is already multi-lingual but a user can’t choose the output language.
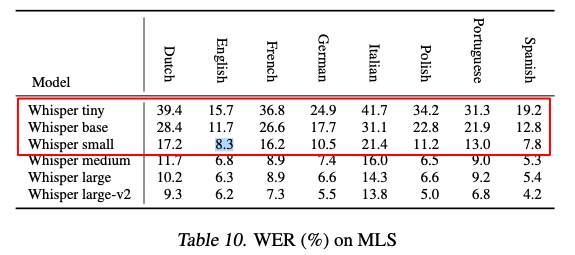
The Whisper Paper has figures for WER scores for all supported languages and datasets, but here’s the results on LibreSpeech. On a mobile device up to “small” is practical:
I’ll also add storage of transcriptions on your device and iCloud, so you have a history.
Payments
To support further development I’ll have to add payments, but the current functionality will remain free. What I’m thinking is charging $1 for 60mins of transcriptions as an in-app purchase. The “Tiny” model will remain free.
I’m very happy to add you to the list of Beta testers if you ask, which will give you everything for free if you agree to do some Beta testing.
If you have some feedback on this let me know at ben@bjnortier.com
Conclusion
In summary, version 1.2.2 is now available and it has real-time dictation.
Up next is user-selectable models, multi-lingual support, and payments.