
Hello Transcribe 3.0
Introduction
Hello Transcribe 3.x for iOS and macOS is now available on the App Store 🙌. This version introduces:
- An improved way to work with Whisper models and options called “Model Configs”, which will speed up your workflows and improve usability.
- Medium and Large Whisper models.
- New Whisper options.
- An improved Whisper framework behind the scenes.
- Other small changes.
Model Configs
Before 3.0 it was really awkward to work with multiple Whisper models and switch between them:
- You could only choose one Whisper model in settings (with associated options like “translate to English”).
- To change the model or an option you would have to do so before you do a transcription.
- On iOS you would have to tap into a separate screen to change a setting.
- There was no way you could use a “fast” model to get a quick result (e.g. when translating a Voice Note) and then choose a more accurate (slower) model to improve the result.
Hello Transcribe 3.0 introduces Model Configs which allows you to do the following:
- Set up multiple configurations with different models and options. For example, you can have “FastEN” and “FastDE” and “AccurateEN” configs for Fast English, Fast German and Accurate English situations.
- You can switch config after a transcription has already started both when dictating or transcribing a file. This will restart the transcription (including the entire input from the microphone from when you started).
- You can alter transcription options on the fly, for example turn of “translation to English”, without having to create a separate config. This will restart the transcription from the beginning.
- Model Configs are synced across devices with CloudKit.
Working with Model Configs
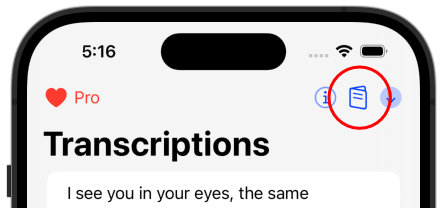
To create or edit your config tap or click on the card icon:
Then tap on the “+” to create a new config with the model and options you want:
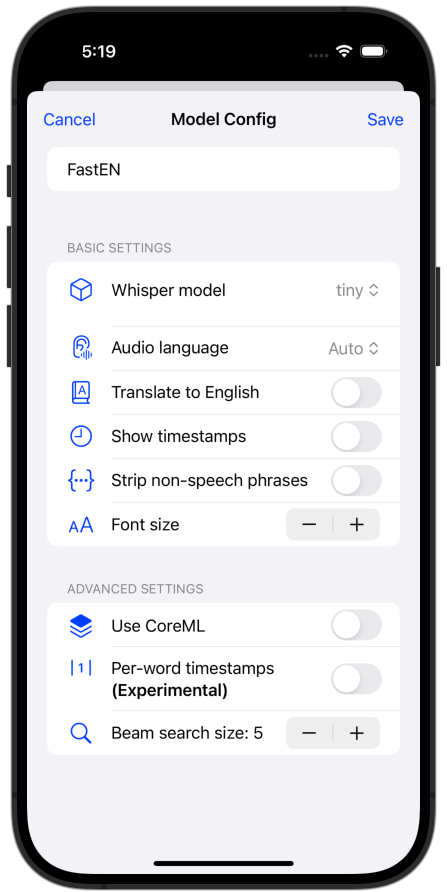
After saving the config any models you need will automatically download.
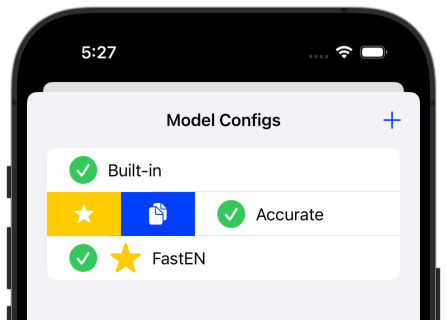
For example here I have two configs along with the built-in config (which uses Whisper “tiny”). You can set the default or copy an existing config by swiping from the left (right or ctrl+click on Mac):
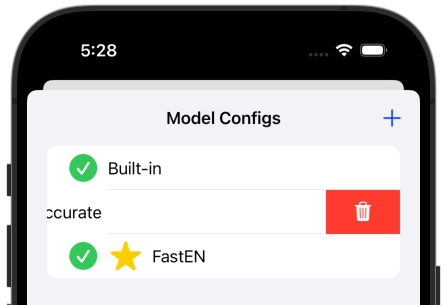
And swipe from right to delete:
The built-in config cannot be removed but can be hidden from the dropdown list of configs:
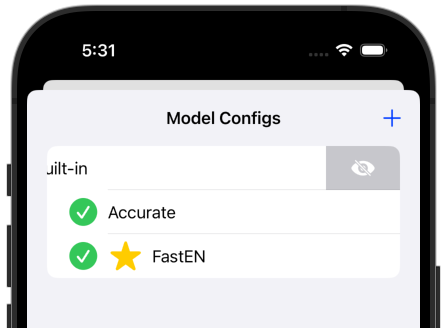
In the transcription screen you can select the config:
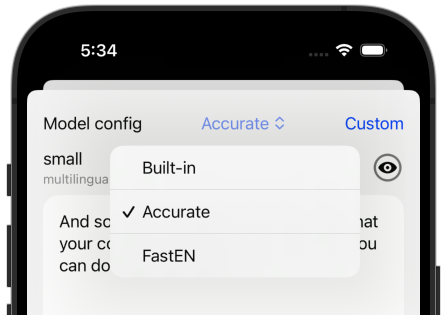
Or use a custom config:
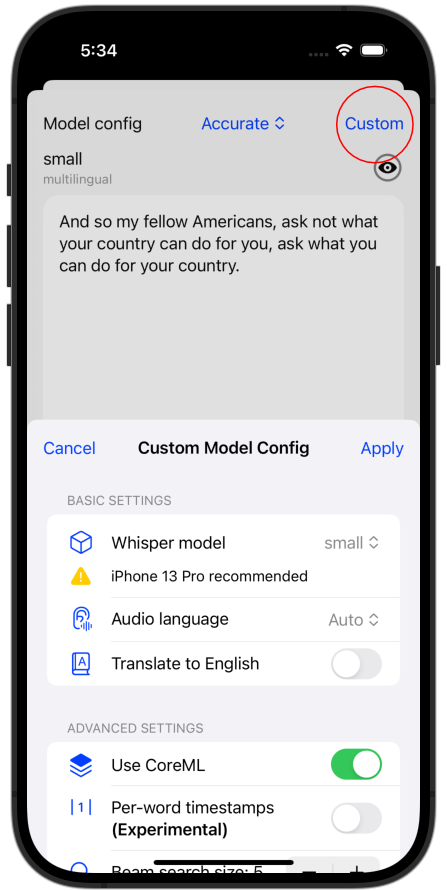
Medium and Large Whisper models
You can now use “Medium” (English and Multilingual) and “Large” Whisper models in the app. These have improved accuracy but require a lot more processing power. They also don’t have CoreML versions.
Support on iOS for Medium and Large is experimental. I have an iPhone 14 Pro and Medium works but it is pretty slow. I don’t have an iPhone 15 Pro to test so I’m not sure about what’s possible. On a technical note, I have now included the entitlement in the build to use more memory in the app, so it should help with the bigger models.
On an M1 Mac Medium and Large are more usable but again your mileage may vary.
New Whisper options
There are two new options you can use:
- Per-word timestamps (experimental). This option will generate a timestamp for every transcribed word, instead of phrases. This is useful if you want to identify specific words of audio in a transcription.
- Beam search size. The way Whisper works is that there’s a graph of potential transcription outputs with their associated probabilities. Beam search is how far to “look ahead” to choose the best output at the cost of processing time. You can reduce the beam search size to produce a faster result but you will lose accuracy. Before 3.0 Hello Transcribe used a beam size of 0, and now the default is 5, so you should see an increase in accuracy (with a small loss of performance). If you really want speed you can reduce the beam search size.
WhisperKit2
Behind the scenes I use a framework I wrote to add iOS/macOS functionality to Whisper.cpp that I called “WhisperKit”. For 3.0 I have rewritten a large amount of that framework to support model configs, add new options, and improve the API.
Contact me if you’re interested in using this framework in a project or want a custom implementation. At some point this framework will probably go open source if I can afford to spend more time on it.
Other changes
Some smaller changes include:
- A new icon:

- The app should stay active on iOS while transcribing.
- The rendering options are now under the “eye” icon.
- The options used to generate the transcription are hidden unless you tap the model text in the result screen.
- The sharing menu has been consolidated.
Conclusion
I’m not sure what the future holds for the app, it’s not really making any money to make it worth the effort to add lots more features. What I would like to do is improve support for Shortcuts to support better transcription workflows. It appears that CoreML might be dropped in Whisper.cpp (for no loss of performance). That would really make the app simpler, so I’m waiting to see what happens with that.
I hope you find the changes have improved the app for you, let me know.