
Hello Transcribe 3.2 🚀
Exciting day today for Hello Transcribe, because version 3.2 is now available, and it about 400% faster. It also adds support for the new Large Version 3 model and fast aborts.
How is it so much faster?
Thanks to the work of Georgi Gerganov, there are two major improvements to whisper.cpp version 1.5.0:
- Using Metal on the GPU instead of CoreML for encoding.
- Batched decode for faster decoding.
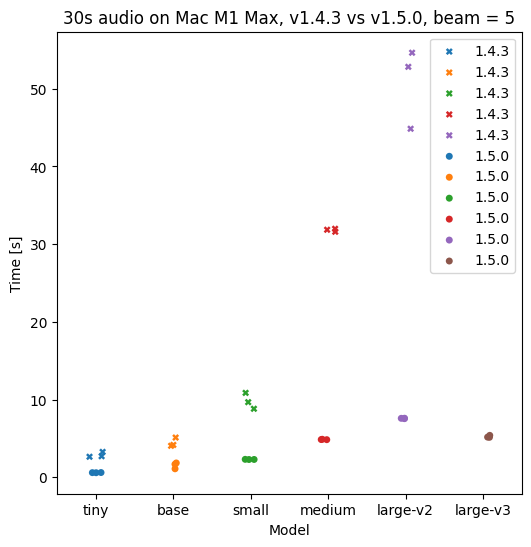
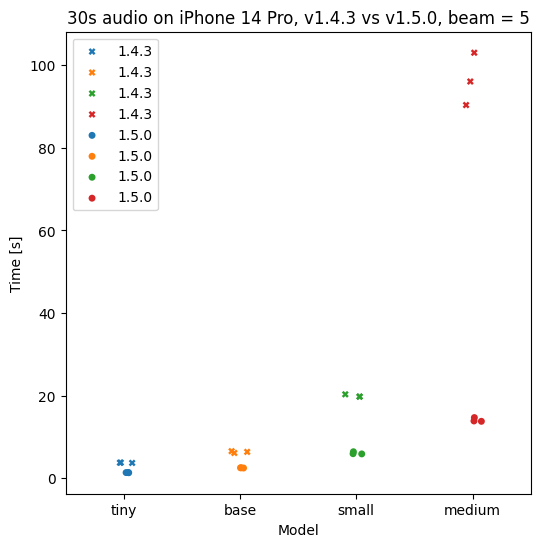
This has led to major performance and usability improvements for Hello Transcribe. Here is what you can expect on an iPhone or Mac for processing times:
| Model | iPhone 14 Pro | Mac M1 Max |
|---|---|---|
| tiny | -64% | -79% |
| base | -61% | -65% |
| small | -70% | -76% |
| medium | -85% | -84% |
| large-v2 | -85% |
and if you prefer graphs… M1 Max:
iPhone 14 Pro:
Metal vs CoreML encoder
Whisper.cpp (and Hello Transcribe) now runs the encoding step on the GPU with Metal.
Whisper has two major steps that impact performance (and some other minor ones): encoding and decoding. Now the encoder runs on the GPU instead of the Apple Neural Engine (ANE).
Previously it was very difficult for me to communicate when to use CoreML because it had some problems:
- It requires an optimisation and caching step which could crash the app due to memory constraints.
- It wasn’t practical for the bigger models (Medium and Large) because the optimisation step could take VERY long (hours).
- I had no control over the cache so sometimes the OS would delete the cached CoreML model.
- There was an issue on macOS 13 with Small (17minutes to cache).
- It required an additional download.
Now users will be less confused and get better results and the recommendation will be simple:
- Majority of users: Just use a bigger model for more accurate results.
- Advanced users: Optionally tune the beam search size (see below).
Batched decoding and beam search size
Whisper.cpp 1.5.0 also includes batched decoding, which makes decoding much faster. Before 1.5.0 a bigger beam search would give more accurate results, but with a significant performance penalty. I didn’t have a good guide for tuning beam search size but now I do.
What is beam search? “In computer science, beam search is a heuristic search algorithm that explores a graph by expanding the most promising node in a limited set.”.
Basically Whisper will calculate a graph of potential tokens. To find the best transcription you can search ahead for the N tokens with the best combined probability, instead of just choosing the first one with the best probability (Greedy search).
When should you tune beam search size? The default is 5 and I would use that. This is what they use in the Whisper paper. If you need more speed, you can decrease it, but I’ve seen some jumbled results with greedy.
Let’s look at a graph of transcription time vs Word Error Rate (WER). WER is a measure of how many words are wrong and lower is better. A WER of 0% is a perfect transcription.
I have plotted the transcription times for each model for 30 seconds of audio, against the WER for the Fleurs dataset (taken from the Whisper Paper and the new Large V3 announcement):
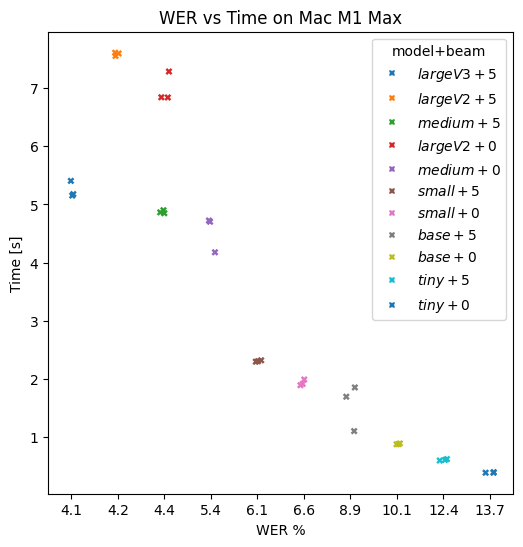
Some things to note. Beam search size is in brackets[] an 0 is greedy:
- LargeV3[5] performs considerably better than LargeV2[5] if you take both WER and processing time into account.
- LargeV3[5] takes only slight longer than Medium[5] but has 4.1 vs 4.4 WER.
- I don’t have a WER number for LargeV3[0] as it hasn’t been published to my knowledge.
It obviously depends on your device but unless you REALLY need speed I wouldn’t use tiny anymore. On my phone I would use Base[5] for “fast”, Small[5] for “balanced”, and Medium[5] on iPhone and Large-V2[5] on Mac for “accurate”.
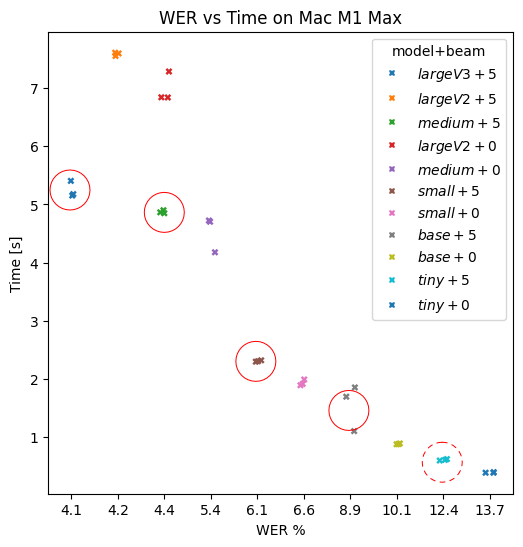
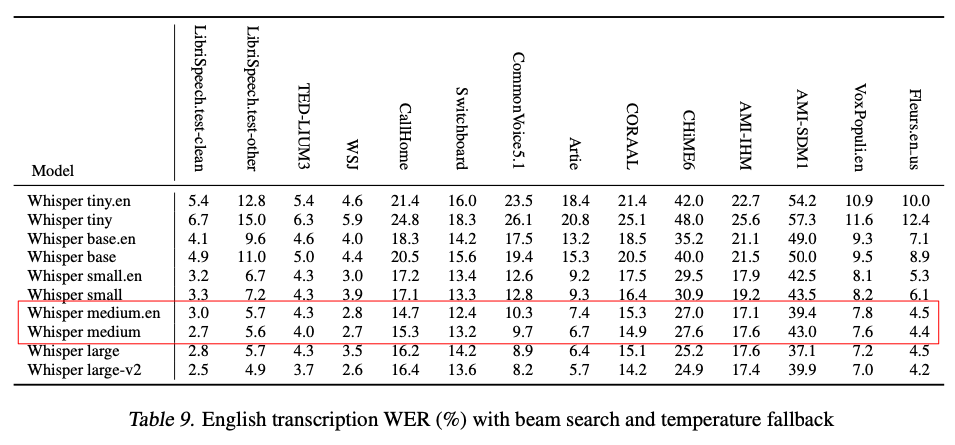
Secondly, using the .en version of the model has an impact. The .en version of Tiny, Base and Small are better than the multilingual versions for English, but Medium is actually more accurate than Medium.en for English for the majority of datasets:
Thirdly, explicitly setting the audio language removes the language detection step which will have a small speed benefit.
To summarise:
- Choose Tiny, Base, Small, Medium or LargeV2 with the default beam search size of 5 depending on your speed/accuracy trade-off.
- Choose the .en version of Tiny, Base, and Small when transcribing English, but NOT Medium.en.
Quick one - fast aborts
Before Hello Transcribe 3.2 cancelling or stopping a big model (Medium or Large) could take quite a while because the transcription process was in C++ land and there was no way to stop it. Whisper.cpp 1.5.0 has a new abort mechanism which can short-circuit the encoder or decoder and exit the process quickly.
Now stopping or cancelling will take at most a second or two.
The future simplified
I introduced Model Configs into the app as a mechanism to manage the complexities of model configuration, CoreML selection, etc. I also wanted to avoid the situation where you could wait for a long time because you used a big model previously and now it’s taking a minute to cancel.
Now with things much simpler and more elegant I am considering removing model configs and replacing it with a mechanism to simply choose the accuracy required (tiny, base, small, medium [and large for macOS]). Choosing English will automatically choose the .en model for tiny, base and small. Beam size will be 5. But I will still provide advanced users access to all the settings. Restarting with a new setting is very quick so the app can be more dynamic.
The other major change that is coming is flipping the app from being transcription-centric to audio-centric. What does this mean?
- The audio (or video) which is the source of the transcription will become the primary object and will be retained.
- You will be able to play back the audio or video with the transcription, highlighting the current position in the text karaoke-style.
- You can have multiple transcriptions for the same input to compare.
- iCloud sync will be optional (which you want to avoid for large data files).
Onwards.